Testing Your Ability at Spotting Lookalike Domain Names
Sunday 12th January 2020
I have created a web-based JavaScript app/game which allows you test your ability at spotting potential lookalike or phishing domains in real-time.

A screenshot of the Lookalike Domain Names Test app.
The app displays the domain name of a well-known website, with a random set of permutations applied to it. You must then select whether the domain is 'Real' or a potential 'Lookalike'.
Lookalike domain names are a very effective phishing technique, as they exploit the natural way that the human brain interprets writing. The brain will automatically make assumptions and fill in gaps when reading, allowing users to be easily fooled if a phishing domain looks almost identical to the legitimate domain.
Skip to Section:
Testing Your Ability at Spotting Lookalike Domain Names ┣━━ Why did I create the app? ┣━━ Predictions and Findings ┣━━ How does the app work? ┣━━ Permutation Methods ┣━━ Content Security Policy and Subresource Integrity ┗━━ Conclusion
Why did I create the app?
Ever since I became interested in IT security, one of my primary concerns and interests has been lookalike domains and how they can be used to conduct convincing phishing attacks.
My first piece of work in this space was my Chrome Site Whitelist Extension from March 2017, which is a simple browser extension to help users avoid phishing sites in Google search results by highlighting a user-controlled whitelist of sites in green.
A screenshot of my Chrome Site Whitelist Extension in action, showing two whitelisted sites highlighted in green.
I've always wondered about my own ability to quickly identify these lookalike domain names, which is what prompted me to create the Lookalike Domain Names Test. I wanted it to be somewhat fun and interactive, so I opted to gamify it a bit by recording the users' score over 10 rounds and displaying it to them at the end.
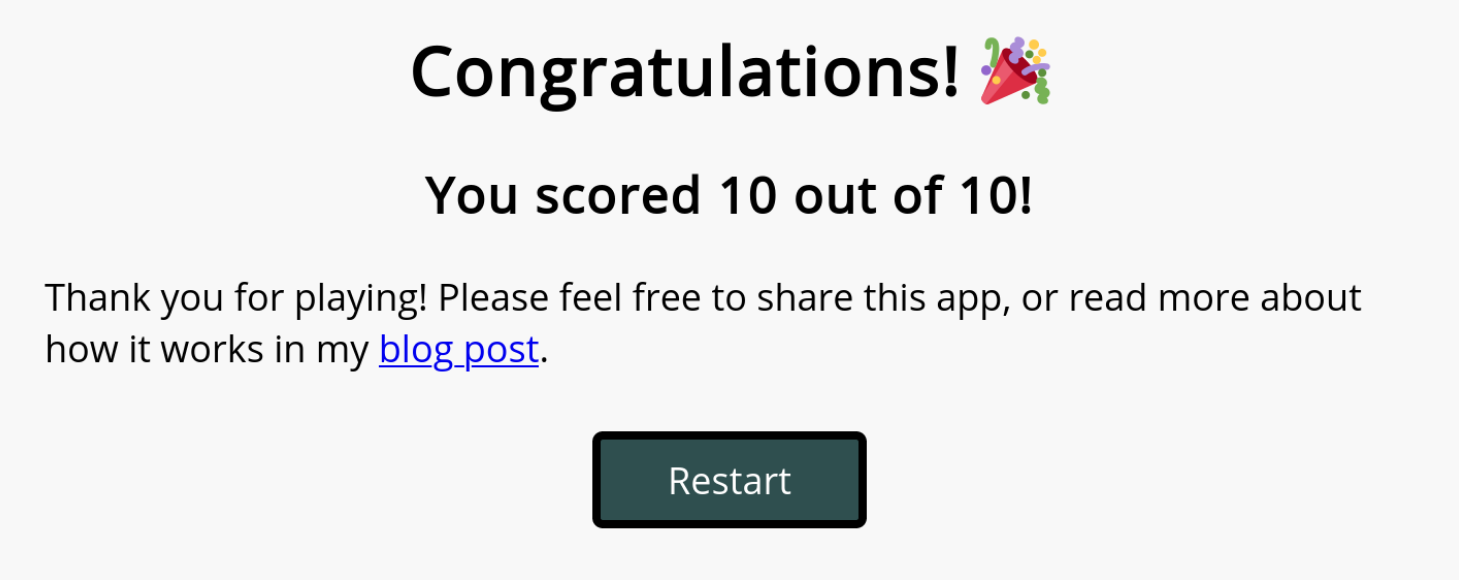
A screenshot of the end-screen in the Lookalike Domain Names Test app.
This project is also the first time that I have allowed myself to utilise JavaScript on my website. Back in 2016 when I started this version of my site, one of the core design decisions was that the site would be completely JavaScript-free, in order to improve performance, security, accessibility and readability. As part of this project, I have now decided to relax this decision ever so slightly in order to allow for the creation of JavaScript 'apps' in select areas of the site. Friendliness to non-JavaScript users is still a core value of my site, and JavaScript will only be used for specific 'apps' that cannot otherwise be created using raw HTML5/CSS3.
Predictions and Findings
My predictions prior to creating and using the app were that it would be challenging to reliably identify lookalike domains that are almost visually identical when only glancing at them (spending around 1 second on each round), and that the accuracy rate would increase significantly if more time were to be spent per round. This prediction was based on the fact that failing to accurately read text when only shown for a short amount of time is an inherent trait of the human brain and how it interprets strings of text (as I mentioned in the first section of this article).
My actual findings after I had created the app show that, within about 1 second, it is easier than expected to identify permutations where characters had been added/removed, or had their order changed. However, permutations involving certain lookalike/substitute characters, for example m and rn, were able to semi-consistently catch the user out. When spending longer than 1 second on each round, the success rate increased significantly, with only almost visually identical permutations still resulting in an inaccurate determination.
This was absolutely not a scientific study, as it used a very small sample size and users were of course expecting there to be permutations and specifically looking for them (thus increasing the success rate). However, it gives a rough indication of the potential results of a much larger scale and more accurate study. The conclusion also most likely has limited relevance to actual real-life phishing attacks, as in many cases, users do not actually look at the URL, never mind scrutinise it for random permutations.
How does the app work?
The app is written is vanilla/plain JavaScript, and uses click event listeners in order to allow the user to interact with it. The app is entirely client-side and does not send or receive any data, nor does it store any data locally (no cookies, etc).
The core functionality of the app uses a hard-coded list of well-known domain names, based on the top websites worldwide, in the United Kingdom and in the United States. A random domain name is picked for each round, and then domain name text is run through a randomised permutation function.
This permutation function may swap characters around, delete characters, substitute visually similar characters, or do nothing at all. The resulting domain name text is then presented to the user, and they must click the answer they believe to be correct. If the domain on the screen matches the one that was originally picked at random, this means that no permutation took place, so the correct answer is 'Real'. If the domain on the screen doesn't match the one that was originally picked, this means that a permutation must have taken place, so the correct answer is 'Lookalike'.
The users' score is recorded throughout, and is then displayed to them on the end screen once 10 rounds have been completed.
It's also worth noting that the dot/period in the permuted domain names is actually a coloured span element, rather than an actual dot character. This is to ensure that the domains are never accidentally hyperlinked or parsed as visitable sites (e.g. if you highlight a piece of text, browsers will auto-detect valid URLs within it and add an option to the context menu to open it in a new tab, etc).
Permutation Methods
There are several different permutation functions built-in to the app, one of which is picked at random for each round. I've included copies of each of them below for reference:
noop():
Do nothing (no operation). Used to apply no permutation to a domain.
function noop(str) {
return(str);
}
lookalikeChars():
Replace a character with a visually-similar character.
var lookalikes = [
["b", "p"],
["l", "I"],
["m", "rn"],
["m", "n"],
["o", "0"],
["u", "v"],
["v", "u"]
];
function lookalikeChars(str) {
#Pick a random pair of lookalike characters
var lookalike = lookalikes[Math.floor(Math.random() * lookalikes.length)];
#Replace lookalike character within domain string (if any)
return str.replace(lookalike[0], lookalike[1]);
}
swapChars():
Swap two adjacent characters within the domain.
function swapChars(str) {
//Split string into array of chars
var splitStr = str.split("");
//Pick a random char number between 0 and the second-last before the dot
var randChar = Math.floor(Math.random() * (str.split(".")[0].length - 1));
//Store the character to swap
var swapChar = splitStr[randChar + 1];
//Swap the characters
splitStr[randChar + 1] = splitStr[randChar];
splitStr[randChar] = swapChar;
//Join and return the array as a string
return splitStr.join("");
}
dupeChars():
Duplicate a random character within the domain.
function dupeChars(str) {
//Split string into array of chars
var splitStr = str.split("");
//Pick a random char number between 0 and the last before the dot
var randChar = Math.floor(Math.random() * str.split(".")[0].length);
//Duplicate character at index
splitStr.splice(randChar, 0, splitStr[randChar]);
//Join and return the array as a string
return splitStr.join("");
}
delChars():
Delete a random character within the domain.
function delChars(str) {
//Split string into array of chars
var splitStr = str.split("");
//Pick a random char number between 0 ad the last before the dot
var randChar = Math.floor(Math.random() * str.split(".")[0].length);
//Remove character at index
splitStr[randChar] = "";
//Join and return the array as a string
return splitStr.join("");
}
Content Security Policy and Subresource Integrity
One of the primary considerations in creating the app was security. Specifically, ensuring that the app is compliant with the extremely tight Content Security Policy (CSP) that is present on my site. I used the per-page policy features described in the article linked above to enable JavaScript just for the page that the app runs on, and nowhere else on the site.
The custom Content Security Policy directives are specified in the PHP code for the app page, resulting in the default site-wide header being built upon to allow JavaScript to run on the app page only:
content_security_policy(["script-src" => "'self'", "require-sri-for" => "script"]);
All JavaScript code is loaded from my own site (on the same origin), so I do not need to whitelist any third-party sources. JavaScript event listeners are used to listen for clicks on interactive elements in the DOM (buttons), instead of using the traditional HTML 'onclick=' attribute.
var eventListeners = [
["answer-button-lookalike", answerLookalike],
["answer-button-real", answerReal],
["disclaimer-accept-button", startApp],
["next-button-input", nextRound],
["restart-button", resetApp],
["start-button", startApp]
]
eventListeners.forEach(createEventListeners);
function createEventListeners(eventListener) {
document.getElementById(eventListener[0]).addEventListener("click", eventListener[1]);
}
The integrity of the code is also verified using Subresource Integrity (SRI), and the require-sri-for CSP directive is used to ensure that script can only run if it has passed an SRI check (require-sri-for is not yet widely supported in modern browsers, but is a draft feature that will be supported in the future).
The PHP page for the app includes the 'integrity=' attribute, as well as a SHA-384 hash (binary hash output encoded in base 64) of the JavaScript source file:
<script src="lookalike-domains-test.js" integrity="sha384-PCCWbBnQRkcTkpyxLGiE/cHP59k0eimC5MLmUDujpwdCr3rKjcmnET5QstKOFgA4"></script>
For reference, hashes for use with SRI can be generated using the following:
$ openssl dgst -sha384 -binary file.js | base64
Each time the file changes, you'll need to generate a new hash and update the HTML 'integrity=' attribute(s).
Conclusion
Overall I am very happy with the outcome of this project, and it has been a good opportunity to develop using JavaScript, which is not a language I usually use.
If you have any questions or feedback, you are welcome to get in touch.